ブラウザを自動操作しよう Selenium
Selenium のインストール
Selenium は昔から結構ブラウザテストに利用されてきているので有名ドコロかもしれません。
ここでは初めてインストールする環境での操作を行っていきます。
事前環境として、Python を入れています。
- Python version 3.8.3 (anaconda3-2020.07)
で、この状況でまずはインストール
% pip install selenium
で、 Chrome にドライバをインストールします。
今回 Mac 使うので、brew 一発ですが、 Windows なら ドライバー要件 :: Seleniumドキュメント から設定します。
ちなみに Windows の場合別口で、 Chocolatey を使う手段もあります。 Chocolatey Software | Selenium All Drivers 4.0
% pip install selenium
コード: 画像取得
ものは試しに画像として取得。
として、selenium_amazon.py としてこんなのを書くと
from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument('--headless') driver = webdriver.Chrome(options=options) driver.get('https://www.amazon.co.jp/') driver.save_screenshot('amazon.png') driver.quit()

も少し真面目にスクレイピング(Scrapy)
Python を使ってスクレイピングしてみる。
変に商用サービスにスクレイピングすると、規約問題が発生するので、とりあえずは自分のサイトで検証してみた。
準備
まずは Python その他諸々をインストールしよう。
ちなみに自分の Python 環境はいま時点でこんな感じ
- Python 3.7.6
- Scrapy 2.4.1 ←公式リンク
特に特筆すべきものではないかもね。
では、Scrapy をインストール
% pip install scrapy Collecting scrapy Downloading Scrapy-2.4.1-py2.py3-none-any.whl (239 kB) |████████████████████████████████| 239 kB 9.3 MB/s ... 中略 Successfully built protego PyDispatcher Installing collected packages: cssselect, w3lib, parsel, protego, itemadapter, jmespath, itemloaders, zope.interface, pyasn1, pyasn1-modules, service-identity, queuelib, PyDispatcher, incremental, constantly, Automat, hyperlink, PyHamcrest, Twisted, scrapy Successfully installed Automat-20.2.0 PyDispatcher-2.0.5 PyHamcrest-2.0.2 Twisted-20.3.0 constantly-15.1.0 cssselect-1.1.0 hyperlink-20.0.1 incremental-17.5.0 itemadapter-0.2.0 itemloaders-1.0.4 jmespath-0.10.0 parsel-1.6.0 protego-0.1.16 pyasn1-0.4.8 pyasn1-modules-0.2.8 queuelib-1.5.0 scrapy-2.4.1 service-identity-18.1.0 w3lib-1.22.0 zope.interface-5.2.0
で、バージョンを確認してみると
% scrapy version Scrapy 2.4.1
早速プロジェクトを開始
プロジェクトをまずは作成
% scrapy startproject white_azalea New Scrapy project 'white_azalea', using template directory '/Users/armeria/.pyenv/versions/anaconda3-2020.02/lib/python3.7/site-packages/scrapy/templates/project', created in: /Users/xxxxx/workspace/scraping/white_azalea You can start your first spider with: cd white_azalea scrapy genspider example example.com

で、軽めに調べたら
- spiders : クロール対象のサイトへのリクエスト/レスポンスのパース処理定義
- items : 抽出するデータ形式の定義
- pipeline : spiders から入ってきた Items の処理を記述。ファイルに保存するとか
では、スパイダー定義を作成してみますか
ブログデータの型定義
items.py をしれっと書き換える。
デフォルトのクラス名とかあるけど、あんまり意味のあるものではないらしい。
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class BlogPost(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() url = scrapy.Field() title = scrapy.Field() date = scrapy.Field()
まぁコレでいいでしょ
Spider 追加
コレはコマンドから
続きを読むChrome拡張をやってみる
Chrome 拡張いじれれば、色々便利じゃまいかと思ってとりあえず気の赴くままに作ってみた。
仕様は、現在開いているURLを markdown 書式でメモリにコピーするプラグイン
あくまで目標は Chrome 拡張をやってみるということで…
Hello world から
どこから初めていいかわからなければ、とりあえずは Hello world からは基本かなと。
これをやるにあたって、まずはこのサイト
なるほど manifest.json が実質の肝なのか、ならこっちも調べて
manifest.json
{
"name": "Url md copy",
"version": "0.1.0",
"manifest_version": 2,
"description": "Sample Chrome Extension",
"author": "white-azalea",
"content_scripts": [
{
"matches": [
"<all_urls>"
],
"js": [
"scripts/main.js"
]
}
]
}
scripts/main.json
window.alert('Hello extension!');
インストールには
そして適当なサイトを開くと…
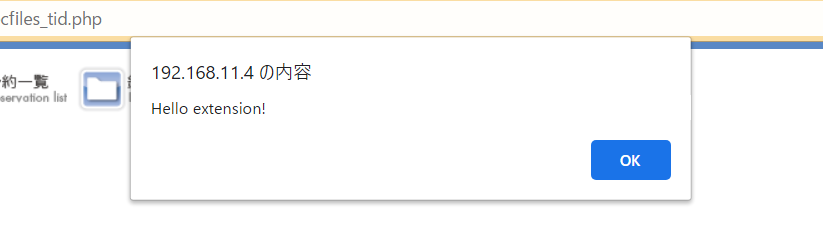
因みに、ここでスタイルをいじくったりできる模様。
Virtual dom 要素は厳しい気がする…(未検証)
尚、Chrome 拡張機能のいくつかの機能は、この js では利用できないらしい。
例えばタブアクセス API の類は、background か、popup の中のJsでしかコールできない模様。
やってみないとわからないが意外と罠が多い。
ポップアップの追加
続きを読むMarkdown や Restructured Text ですべてのドキュメントを解決したい Pandoc
まず最初に言っておくこととして、自分は Office 製品が嫌いである。
それはどれくらい嫌いかというと、スライドですら Marp で作りたくなるくらいである。
で、そんな Markdown 信者でも Word のドキュメントや、PDF にする必要に迫られることはあるわけで、そんなとき結構困るわけです。
一度HTMLにしてPDF化して…なんてしてたわけですが、これで解決できるならその方が絶対にいい!
ってことで早速使ってみる。
Install
Pandoc公式 から Installing で見てみると、brew や choco に対応してる!
万歳!
choco install pandoc
Mac なら
brew install pandoc
いいねぇ
試してみる
お試しドキュメントはここの README ファイル。
で、色々試してみる
PS C:\Workspace\WelcomePythonExamples> pandoc .\README.md -o readmme.html PS C:\Workspace\WelcomePythonExamples> pandoc .\README.md -o readmme.docx PS C:\Workspace\WelcomePythonExamples> pandoc .\README.md -o readmme.tex PS C:\Workspace\WelcomePythonExamples> pandoc .\README.md -o readmme.rst
- html
- docx
\hypertarget{welcomepythonexamples}{% \section{WelcomePythonExamples}\label{welcomepythonexamples}} Python3.7+ から始める非 Python 利用者向けの、「Pythonでこんなことできるよ」の説明用リポジトリです。\\ あまり深い内容には言及せず、紹介程度にサンプルを記述するリポジトリです。 「こんなのもPythonらしいしやってほしい、紹介してほしい」などがあればプルリクでも Issues でもお願いします。\\ Issues にどれくらい書き込まれるかは不明ですが、できる範囲かつ、やる気のある物を対応していく方針です。\\ 無償かつ趣味でやってますのでその辺りはご容赦を。 \hypertarget{ux306fux3058ux3081ux306b-python-ux306eux5229ux70b9}{% \subsection{はじめに Python の利点}\label{ux306fux3058ux3081ux306b-python-ux306eux5229ux70b9}} ...
- rst
WelcomePythonExamples ===================== | Python3.7+ から始める非 Python 利用者向けの、「Pythonでこんなことできるよ」の説明用リポジトリです。 | あまり深い内容には言及せず、紹介程度にサンプルを記述するリポジトリです。 | 「こんなのもPythonらしいしやってほしい、紹介してほしい」などがあればプルリクでも Issues でもお願いします。 | Issues にどれくらい書き込まれるかは不明ですが、できる範囲かつ、やる気のある物を対応していく方針です。 | 無償かつ趣味でやってますのでその辺りはご容赦を。 はじめに Python の利点 ---------------------- スクリプト言語で速攻開始できる ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ | Python はスクリプト言語なので、テキストソースをそのまま実行できます。 | これは書いてすぐ試せるという利点に繋がります。
”Wordに根をおろし、Excelとともに生きよう。PowerPointとともに冬を越え、Accessとともに春を歌おう”。どんなに恐ろしい武器を持っても、たくさんの可哀想なOSSを操っても、Office から離れては生きられないのよ
うっせぇ〇ータ!
プレーテキストを校正チェックする
Word などに校正ツールはますが、Markdown や ReStructuredText などのプレーンテキストを校正する手段には乏しいです。
まさかこのためだけに pandoc で word ファイルを作るとか、ワードを起動するとか、腹立たしいことこの上ありません。
そこで、ツールを利用して文章チェックを行う事を考えます。
これが Textlint です。
検証した環境は
- nodejs : v14.15.2
- npm: 6.14.9
まずはインストール
npm install -g \
textlint \
textlint-rule-preset-ja-spacing \
textlint-rule-preset-ja-technical-writing \
textlint-rule-spellcheck-tech-word \
textlint-rule-no-mix-dearu-desumasu
これで必要分はインストール済み。
セットアップ
これは最初にコマンド textlint --init を実行すると、.textlintrc ファイルが作成されます。
ここに以下のような設定を行いました
{ "filters": {}, "rules": { "preset-ja-spacing": true, "preset-ja-technical-writing": true, "spellcheck-tech-word": true, "no-mix-dearu-desumasu": true } }
これで設定完了。
実行
ということで、シンプルに以下のような文章を食わせてみました
# Mockpex について Mockpex は Salesforce テスト用ライブラリです。 用途として、Apex でのテストコードを実装するにあたり、各種モックアップやスタブ作成の支援を行います。
さぁこれでどう出るか?
$ textlint README.md
/mnt/c/Workspace/Mockpex/Mockpex/README.md
3:8 ✓ error 原則として、全角文字と半角文字の間にスペースを入れません。
ja-spacing/ja-space-between-half-and-full-width
3:10 ✓ error 原則として、全角文字と半角文字の間にスペースを入れません。
ja-spacing/ja-space-between-half-and-full-width
3:21 ✓ error 原則として、全角文字と半角文字の間にスペースを入れません。
ja-spacing/ja-space-between-half-and-full-width
4:11 ✓ error 原則として、全角文字と半角文字の間にスペースを入れません。
ja-spacing/ja-space-between-half-and-full-width
4:45 error 【dict5】 "支援を行う"は冗長な表現です。"支援する"など簡潔な表現にすると文章が明瞭になります
。
解説: https://github.com/textlint-ja/textlint-rule-ja-no-redundant-expression#dict5 ja-technical-writing/ja-no-redundant-expression
✖ 5 problems (5 errors, 0 warnings)
✓ 4 fixable problems.
Try to run: $ textlint --fix [file]
うーんなかなか心に来る指摘をありがとう(TT
Ui Path で簡単スクレイピング
スクレイピングというのは、サイトの内容を自動で抽出する操作の事。
ニュースサイトでは通常、RSSとか配信してるけど、そういう情報がないサイトに対しては有効です。
ものは試しという事で、Engaget からトップニュースをしれっととってみる。
Ui Path のインストール
個人で使う分には Community で大丈夫でしょう。
今はインストーラーが一つにまとまってるので、CommunityLicense でインストールしませう。
インストールが終わったら、Chrome 拡張をインストールします。
これでとりあえずは事前準備済みです。
スクレイピングの設定
まずはサイトを表示してしまいます。
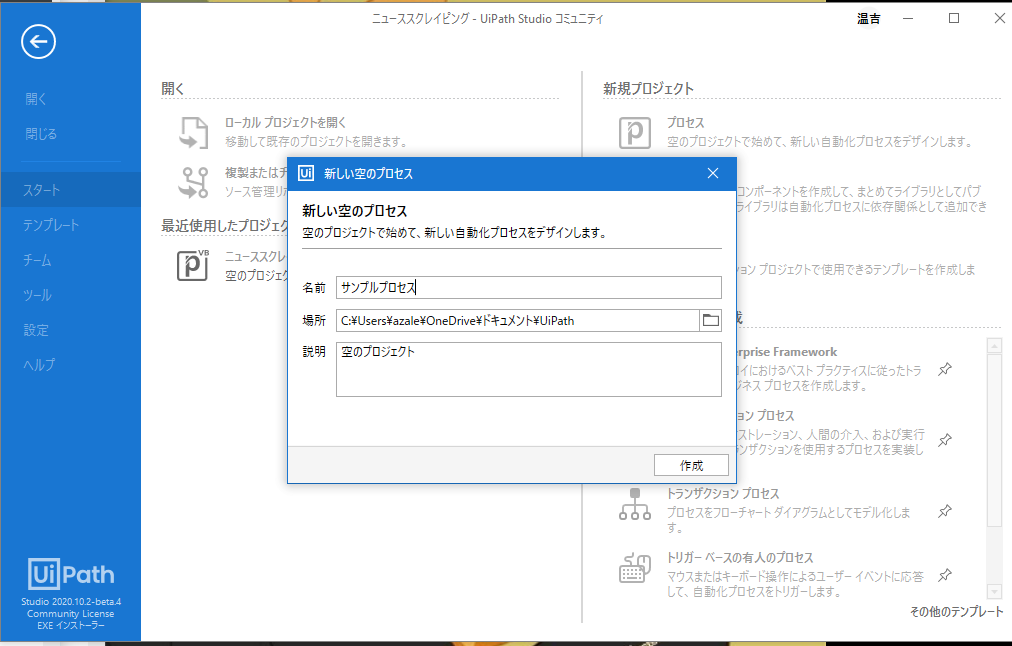
で、Ui Path で新規プロジェクトを開始して、プロセスを作成します。
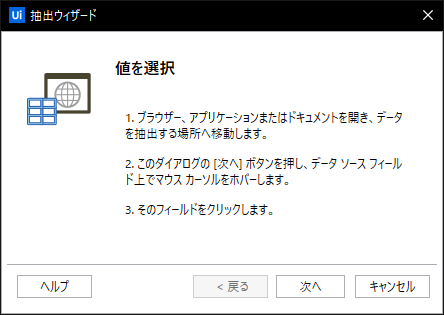
そしたら「データスクレイピング」を開始して「次へ」

そこで、まずは最新記事を選択
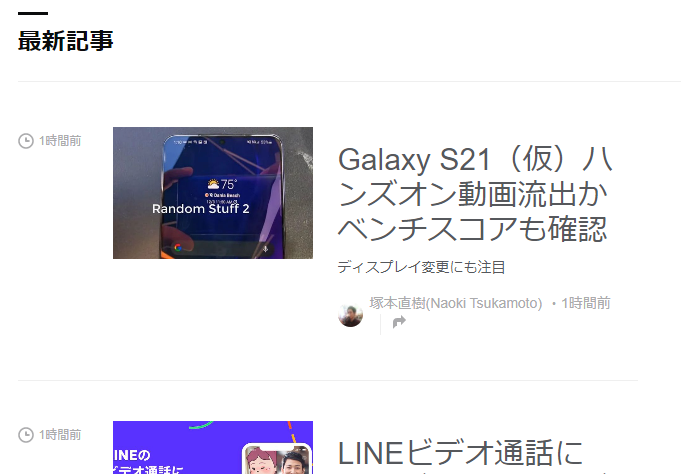
二番目の要素といわれるので、最後の記事のラベルを選択しよう

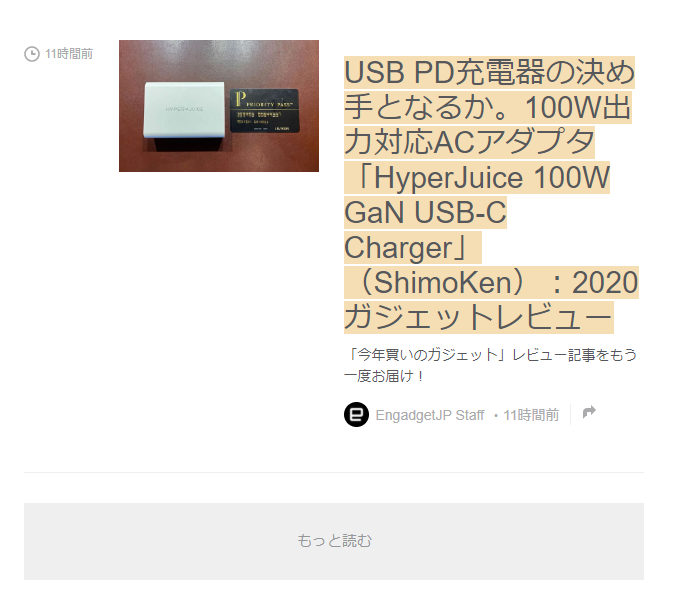
後はそのまま次へ進んで
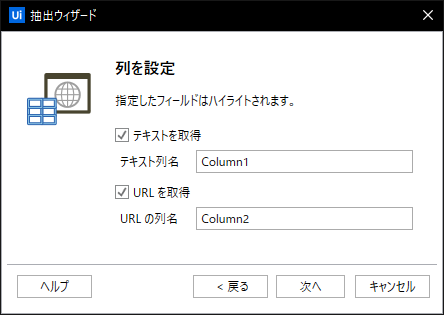
完了
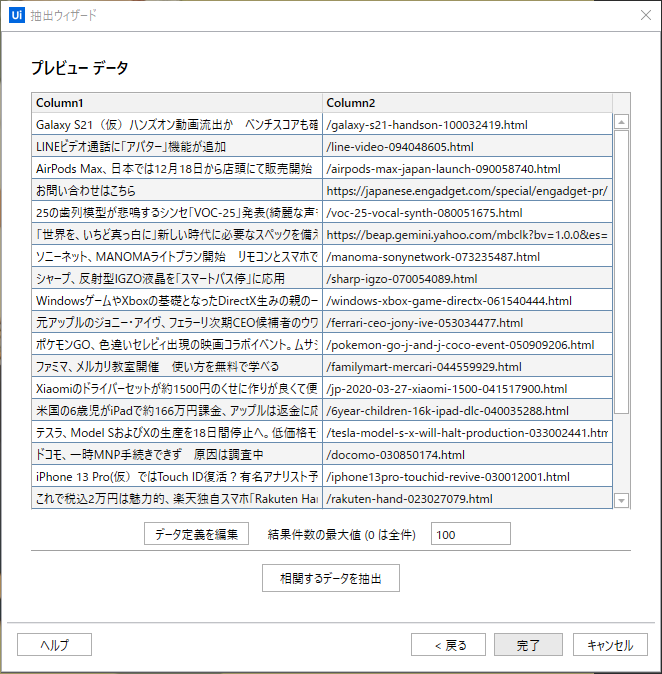
複数ページへまたがるので「もっと読む」を選択します。
するとこんな感じになるので
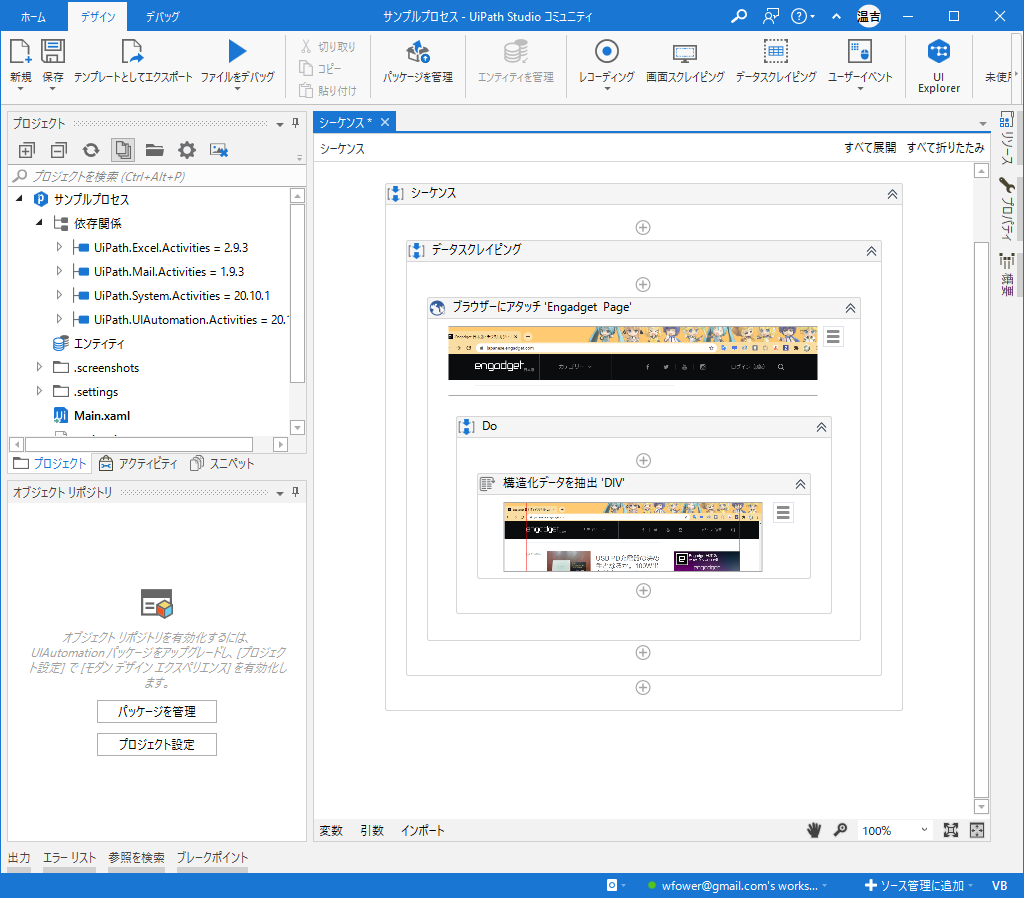
追加でコマンドを突っ込みましょう
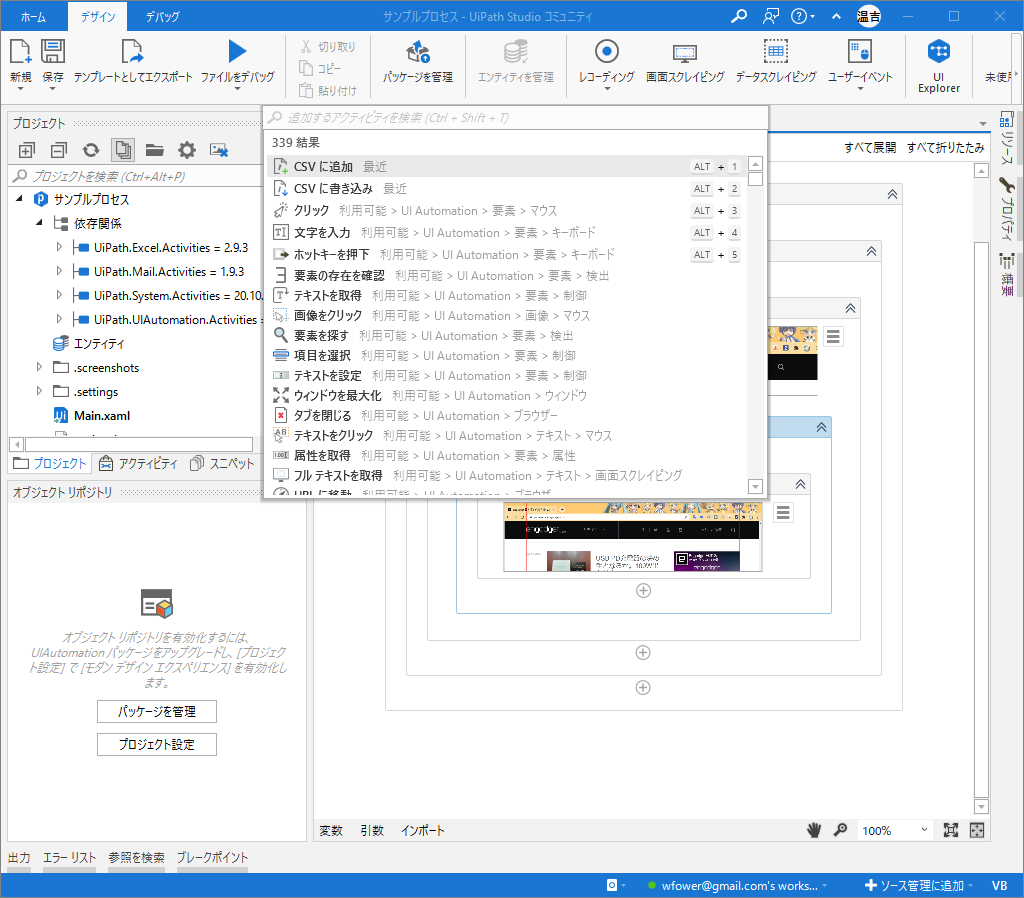
そしてシーケンスを作成して、適当なCSVに追加保存。
追加するデータは「ExtractDataTable」
そして実行すると

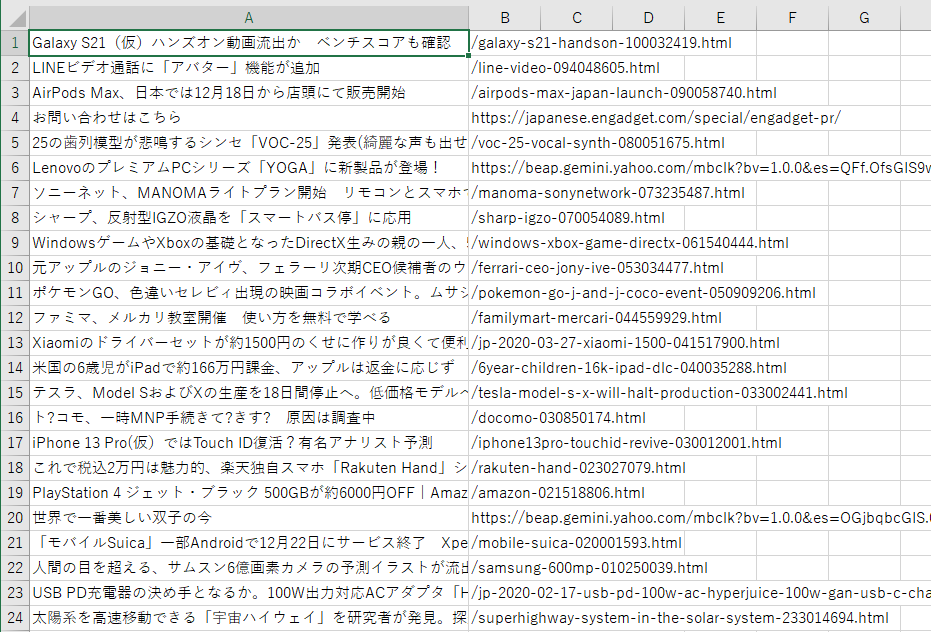
ひゃっほい
LightningWebComponent(OSS)で Bootstrap を読み込む
LightningWebComponent をイジってみて、Web Component としてシンプルだなーOSS版も使ってみるかなーと思ったらいきなりドハマリしたのでメモ。
OSS版 LWC を始める
といってもやり方は恐ろしく単純で
$ npx create-lwc-app my-app
これだけでテンプレができる。
とりあえず Web アプリを指定した。
$ npm run watch
これで http://loclhost:3002 にサーバが立つので実行できる。
Bootstrap を読み込んだ(失敗版)
まず、Bootstrap を読み込んで失敗したケース。
index.html でこんなことをしてみたのだが
<!-- styles --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css" integrity="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk" crossorigin="anonymous"> <!-- js --> <script src="https://code.jquery.com/jquery-3.5.1.slim.min.js" integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj" crossorigin="anonymous"></script> <script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/js/bootstrap.min.js" integrity="sha384-OgVRvuATP1z7JjHLkuOU7Xw704+h835Lr+6QL9UvYjZE3Ipu6Tp75j7Bh/kR0JKI" crossorigin="anonymous"></script>
適用される範囲は LWC アプリケーションの外側のみという残念なことに。
何が起こったのかと思って挙動を調べて見ると、どうも shadow dom はコンポーネント毎に style が完全独立してて、相互の CSS の影響をうけないんだとかなんとか…
共通的なフォントサイズとかフォントファミリとかどないせーっちゅーねん(汗
と思って調べて見ると
Because native Shadow DOM is enabled out-of-the-box for Open Source, you can’t just use a global stylesheet that then allows to cascade styles across inheriting Lightning web components. Everything is truly encapsulated, which is one of the huge benefits. ネイティブのShadowDOMはオープンソースですぐに使用できるため、継承するLightningWebコンポーネント間でスタイルをカスケードできるグローバルスタイルシートを使用することはできません。すべてが本当にカプセル化されており、これは大きなメリットの1つです。 You will have to rethink your CSS strategy when it comes to building Lightning web components, or if you want to reuse components that you built and styled on Lightning Platform. Lightning Webコンポーネントの構築に関して、またはLightning Platformで構築およびスタイル設定したコンポーネントを再利用する場合は、CSS戦略を再考する必要があります。 On the other side, you can choose with LWC Open Source to use synthetic shadow as an easier way to interoperate with existing UI if needed. 一方、必要に応じて既存のUIと相互運用するためのより簡単な方法として、合成シャドウを使用するようにLWCオープンソースを選択できます。
Oh...
共通CSS取り込み戦略
ということで、共通CSSを取り込み戦略を調べて見ると
実際にやってみると

CSS だけのモジュールを用意して

こんな感じで実行すると

てな感じ。
でも目標はあくまで Bootstrap を使うこと。
なので、一旦は cssCommon を削除する(次のトライの邪魔になる)。
Bootstrap を取り込む戦術
Bootstrap を npm 経由で取り込んで CSS で取り込む。
$ npm install bootstrap
としたら、lwc-services.config.js ファイルを開いて、resources をいじくります
module.exports = {
resources: [
{ from: 'src/client/resources/', to: 'dist/resources/' },
{ from: 'node_modules/bootstrap/dist', to: 'src/bootstrap' },
{ from: 'node_modules/bootstrap/dist', to: 'dist/bootstrap' }
],
// 以下略
ここまで書いたら、
npm run build:development
実行するとこんな感じになる

ソースディレクトリに Bootstrap を強制配置。
ここまでやったら、全てのコンポーネントの先頭でこんな事すればまずは Bootstrap が使える。
<template> <link href="/styles/salesforce-lightning-design-system.css" rel="stylesheet" type="text/css" /> </template>
ただし、コレだとコンポーネントすべてで書かなきゃいけないので色々ダメ。
なので、もう少しアレな手段をとってみる。
さっきのように cssCommon コンポーネントを作るけど、今度は Javascript ファイルのみ用意する。
中身はコレ
import { LightningElement } from 'lwc';
export default class CssCommonElement extends LightningElement {
_bootStrapCss() {
let _bootstrap = '../bootstrap/css/bootstrap.min.css';
const styles = document.createElement('link');
styles.href = _bootstrap;
styles.rel = 'stylesheet';
return styles;
}
connectedCallback() {
// テンプレートに無理やり Bootstrap の CSS 挿入
this.template.appendChild(this._bootStrapCss());
}
}
connectedCallback() はライフサイクルイベントの一種で、親コンポーネントの下に配置された際に実行されるコールバック。
つまり、初期化が終わって、コンポーネントが表示待機状態に入ったことを意味する。
ここで、スタイルシートを無理やり適用している。
あとは画面上に表示されるコンポーネント全てで LightningElement の代わりに CssCommonElement を継承する。
import CssCommonElement from 'todo/cssCommon';
export default class App extends CssCommonElement {}
この状態で html テンプレートに
<template> <button class="btn btn-primary">Bootstrap ぼたーん</button> </template>
と記述すれば

ただし、欠点もある…というのも、CSS ではなくて Js (つまり JQuery を使ったDOM操作)を行う機能はうまく取り込めないらしい。
というのも shadow dom 使ってるせいで、id とかがうまく取れないことが原因のようだ…デスヨネ…
ちなみにこの対応で作ったものがコレ
参考にどうぞ