Salesforce開発の基礎編7
トリガの実行順序
レコードの作成/更新を実行すると、次の順で処理される。
- 変更元レコードがあればまず読み込まれる
- メモリ上で更新後の値を作成する
この時標準UIからの更新であれば、UIに設定されてるバリデーション、項目自体に設定された桁数などのチェックが走る。 - フロートリガが実行される。
フローについては Salesforce開発の基礎編4 - 技術をかじる猫 この辺参照。 - before トリガの実行。トリガの内容はこの辺参照 Salesforce開発の基礎編5 - 技術をかじる猫
- null チェックや桁数チェックが再度起動。これは「before trigger」で値が設定されるためですね。
多分この辺で数式項目が処理されます。 - 重複ルールが実行される。重複ルールはオブジェクトマネージャから設定できる。
- データベースに
insertされる。(transaction commit はまだ実行されてません) after triggerが実行される。- 割り当てルールが実行されます。
- 自動応答ルールが実行される。
- ワークフロールールが実行
- ワークフローの項目更新があればここで更新
- 更新が発生すると、
before insert,after insertトリガが実行される。
- 更新が発生すると、
- プロセスビルダで指定したフローが実行される。実行順序は保証されない。
- エスカレーションルールの実行
- エンタイトルメントルールが実行
- レコードの保存後に実行されるように設定されたレコードトリガフローを実行
- レコードに積み上げ集計項目が含まれる場合、またはレコードがクロスオブジェクトワークフローの一部である場合、計算が実行
- 親オブジェクトのさらに親の積み上げ集計を実行(だからオブジェクトの親子関係は 3階層までしか持てない)
- 共有設定の処理(Summer 21 ではバグで、Process automated/System が所有者だとこの処理が走らない)
- トランザクションコミット
- メール送信など確定後処理
何か trail 進めようかと思ったけど、今日今時点でなぜか 503 なので、今日はここまで。
夏に美味しいお茶シリーズ
あんまりこういう事を書く機会はなかったのだだけど、僕はお茶が好きだ。
コロナでお茶が売れてきてる…という話は聞くのだけど、なればということでこの時期のおすすめ茶を Lupicia と自前の作成から紹介してみる。
主に、普段はあまりお茶や緑茶を飲まない…苦いだけじゃない?とか思ってる人にもかなり楽しめるお茶を紹介する。
基本的に、夏向けで、いずれも水出しでも十分美味しいものばかりだ。
季節限定茶
Lupicia には多くの季節限定茶がある。
これから暑くなるにあたり、この季節特有の夏に良さげな季節限定茶を挙げよう。
レモン風味のさっぱり感 「ハツコイ」「ナツコイ」
グリーンレモンやレモングラスをブレンドした緑茶+紅茶。
安心してほしい酸っぱくはない。ただ風味がレモンの様にさっぱりしているというだけだ。
毎年夏が近づくと販売するお茶である。
柑橘系だがミントも入っててさわやか「ブリティッシュクーラー」
これも水出しがおいしい紅茶だ。
まぁ見出しだけでも風味はなんとなく想像がつくのではなかろうか…
他のフレーバーティー
季節限定…というわけでもないが、これからの季節でおいしいお茶シリーズだ。
桃が香る烏龍茶「白桃烏龍 極品」
桃の風味を冷やして味わう…しかも癖のない烏龍茶。
夏に飲むには最適だろうと思う。
スーッとする緑茶「アラジン」
緑茶にミントを混ぜたフレーバーティ。
風呂上りに冷やして飲みたい逸品である。
ラベンダーで夏らしさを感じようか「コロポックル」
店頭で買おうと思たら北海道に行かないと存在しない地域限定茶。
ハスカップとラベンダーが夏らしさを伝えてくれる逸品だ。
夏だ!フルーツだ!
説明不要なフルーツ系(風味)烏龍茶!
冷やして飲めや!
www.lupicia.com www.lupicia.com
個人的なおすすめブレンド
ジャスミンティーにミントエッセンスやミントの葉を混ぜて飲むのもお勧め。
RNN を考える
RNN って何かというと Recurrent Neural Network 再起構造型ニューラルネットワークの意味。
再帰構造型の意味って何かというと、前回のニューロンの出力と現在の入力を引数にして「前回の状態を含めて判断する」ニューラルネットのこと。
普通、ニューラルネットを扱うとき、活性関数を
学習データを
とし、重み
バイアス
とすると
ニューロンの作りは
ということになる。
ただしこれはその時点でのデータとしたときの問題で、前の状態が次の状態に影響するようなデータには正常に適用できない。
そこで、RNN ではデータ
のある時点のデータを
と仮定して
こんな感じに前回のニューロン応答に追加の重み を加えて取り込む動作をする。
少し展開するとこんな感じ
RNN の活性関数には をよく使われてる。
これはこんな関数らしい
もう少しシンプルな書き方で一般化して
Salesforce開発の基礎編6
データベースと .NET の基本
.NET は忘れていい。というか引きずると超ハメられる。
決して .NET 程リッチなつくりではないのだから…。
SQL から SOQL への移行
- SOQL はあくまで検索機能しかない (insert, update 等は DML であって SOQL ではない)
- SOQL は標準的に
SELECT *はできない(ことになっている)。
調べれば分かるがsummer 21アップデートでFIELDSが入るので、事実上の*はできるようになる。(制限として 200 行以下縛りがある)Salesforce Spring '21の新機能、SOQLのFIELDS()関数について - TerraSkyBase | テラスカイを支える人とテクノロジーの情報を発信する基地局
通常は必要なフィールドを全部列挙する。 - クエリの作成は ワークベンチ を使うこともできる。てーかめんどくさくて普通の開発では使わないけど。
LIKE等は普通に使える。ORDER BYやLIMIT等も普通に使える。JOINはできない。CONTAINも存在しないし、サブクエリも実質存在しない(SQL使いにしてみれば F〇CK YOU! と叫びたくなる)has-a関係やリレーション項目が存在していれば、そこを経由して検索することができる。
SELECT Name, (Select FirstName, LastName FROM Contacts) FROM Account
SOSL クエリの作成
全文検索クエリが使える。SOSL 基盤には Lucene が使われている。
ただしインデックスがどう使われるかは開発者が操作できない…
FIND {"grand*"} IN ALL FIELDS RETURNING Account(Name), Contact(LastName, FirstName, Email)
まぁ割と見たまま過ぎて突っ込むこともないよね。
効率的なクエリの作成
クエリ自体はバックエンドが Oracle なんでオプティマイズはその辺任せ。
デフォルトでは以下の項目にインデックスができる。
インデックスは DB が高速に検索するための設定
- Id
- Name
- OwnerId
- CreatedDate, SystemModStamp
- RecordType
- 主従項目、参照項目
- unique 制約を入れた項目
- 外部ID項目
クエリプランは開発者コンソールから



で出てくる
DML を使用したレコードの変更
開発者コンソールからガンガン行ける。

もしくは insert などのDML句を使おう。Database クラスからでも操作できる。
// Add Account Account acct = new Account( Name='Test Account', Phone='(225)555-8989', NumberOfEmployees=10, BillingCity='Baton Rouge'); Database.SaveResult[] results = Database.insert(acct, false);続きを読む
Salesforce開発の基礎編5
Apex の基礎とデータベース
Apex の使用開始
まぁJava書いてたら特に問題なくやれる。言語仕様は体感 Java1.42 位の印象(1.4 よりはマシ?だが5の様なGenericsなどは存在しない)。
ローカルコンパイルできず、Salesforce 組織上でしかコンパイル/実行できない。
Apex の特徴的な機能として
- クラウド開発 (Apex はクラウドで保管、コンパイル、および実行されるため)
- トリガ (データベースシステムのトリガと類似)
- 直接データベースコールが可能なデータベースステートメントと、データのクエリと検索を行うためのクエリ言語
- トランザクションとロールバック
- global アクセス修飾子 (public 修飾子よりも権限が高く、名前空間とアプリケーションの全体でアクセスが可能)
- カスタムコードのバージョン管理
サンプルのコードは非常にうれしい作りではあるのでここでも転記。
Java だとメールサーバに接続して…なんて色々やるけど、そういった内容はすべて Salesforce にビルトイン。
こういう所は楽っちゃ楽
public class EmailManager { public void sendMail(String address, String subject, String body) { Messaging.SingleEmailMessage mail = new Messaging.SingleEmailMessage(); String[] toAddresses = new String[] {address}; mail.setToAddresses(toAddresses); mail.setSubject(subject); mail.setPlainTextBody(body); Messaging.SendEmailResult[] results = Messaging.sendEmail( new Messaging.SingleEmailMessage[] { mail }); inspectResults(results); } private static Boolean inspectResults(Messaging.SendEmailResult[] results) { Boolean sendResult = true; for (Messaging.SendEmailResult res : results) { if (res.isSuccess()) { System.debug('Email sent successfully'); } else { sendResult = false; System.debug('The following errors occurred: ' + res.getErrors()); } } return sendResult; } }
基本はこっから起動して

クラスを追加

クラス名は StringArrayTest

答えを書いても仕方ないのでテスト内容の翻訳
StringArrayTestというクラスでpublicで作りますpublic staticなメソッドgenerateStringArrayを作成しますgenerateStringArrayの仕様はInteger型の引数List<String>型の返値型- 引数の値によって
Test 0,Test 1... の様な値を返します。
sObject の使用
Salesforce のデータベースはすべてオブジェクト、Apex 的には sObject 型です。
全てのオブジェクトには Id フィールドがあり、プライマリキーです。型も ID 型で、18文字 String 値が入ってます。
sObject は Salesforce開発の基礎編2 - 技術をかじる猫 このデータモデリング参照。
クエリもソース内でこんな風に書ける
List<Account> values = [SELECT Id, Name FROM Account WHERE Name LIKE 'Test%'];
DML を使用したレコードの操作
DML ってのは、要するにレコード操作
insert, delete, update, upsert, undelete, merge でデータを色々いじれる。
Account acct = new Account(Name='Acme', Phone='(415)555-1212', NumberOfEmployees=100); insert acct;
insert や upsert した直後に Id フィールドにだけ値が設定される。
数式項目は insert が完了したときに埋められる…のだけど、insert に使ったオブジェクトには入らないので、select しなおさないといけない。
upsert は insert としても update としても使えるコマンドで、merge は最大 3 レコードを 1 レコードに自動マージして既存レコードを削除して保存される。
一応データベース操作はメソッドでもできる。
Database.insert() Database.update() Database.upsert() Database.delete() Database.undelete() Database.merge()
問題はこんな内容
AccountHandlerクラスを作成しますpublicでね- 以下の仕様を満たす
public staticなinsertNewAccountメソッドを作ります- 引数に
Stringを受け取り、Account オブジェクトを作成、Account.Nameに設定します。 - 作ったら
Accountをinsertし、returnする。 - 引数では空文字も受付け、保存に失敗したら
nullを返します。
- 引数に
SOQL クエリの作成
ソース中にクエリが書ける仕様の演習課題。
public class ContactSearchを作成してくださいpublic staticなメソッドsearchForContactsを定義します。- 二つの
Stringパラメータを受け取ります Contactを検索します。第一引数はLastNameとマッチさせ、第二引数はMailingPostalCodeと一致検索します。- 最終的に
List<Contact>を return します。SELECT 内容は Id, Name です。
- 二つの
ニューロンと過学習の割合を観察する
検証内容
アルゴリズムと過学習の関係をざっくり記載する。
設定は以下の感じ
img_size = 8 n_mid = 32 n_out = 10 eta = 0.001 epochs = 301 batch_size = 32 interval = 10
因みにCNNの特徴抽出はせず、あくまでニューロンでの判定のみで行う。
中間層ニューロンを 32 個、バッチサイズ 32 で、エポック 301 回。
単純にニューロン食わして処理するとこんな感じ。

時間経過で誤差が広がる(過学習)が起きてるというよりは、単純にこのアルゴリズムでは精度が上がらないという事かもしれない。
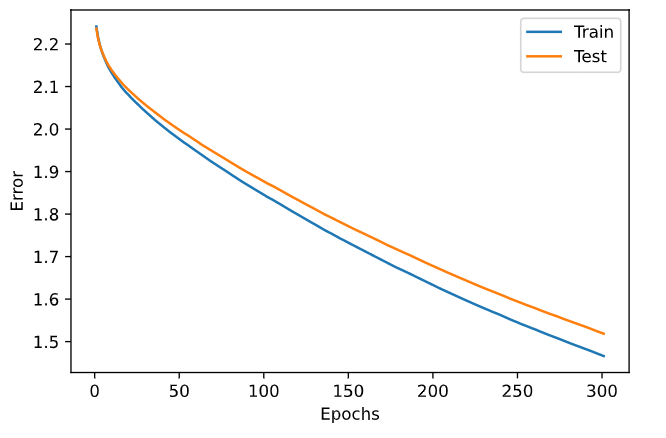
AdaGrad アルゴリズムを適用するとこんな感じ

学習係数に圧がかかってくるので、学習自体が遅くなる。
それによって学習が収束するのがかなり遅くなり、300 回程度では良い結果にならなかった。
ドロップ層を追加したのかこんな感じ
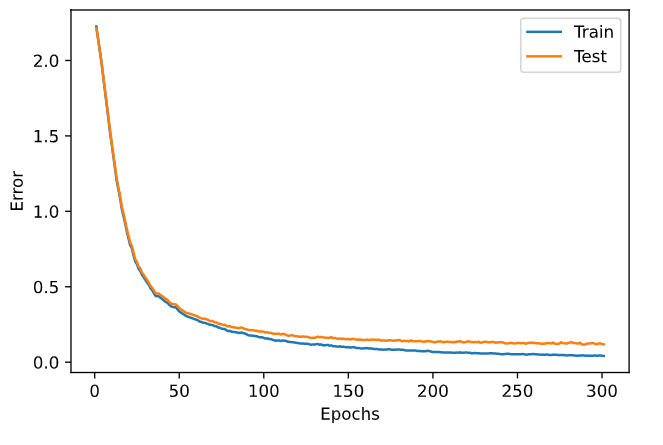
ニューロンの学習が確立的になるので、学習が微妙にガクガクする。
AdaGrad を使うべきかどうかは状況によるのかもしれない。
両方適用するなら、学習回数を更に増やす必要がありそう。
ストレスに関する対策の論文とかを調べてみた
日常でできるストレス対策。
- 緑茶: 含まれるテアニンには向精神作用があります。
https://www.taiyokagaku.com/lab/column/07/
http://www.jsbmg.jp/products/pdf/BG35-4/35-4_9-15.pdf - 背筋を伸ばす: 幸福感を発生させます(コロンビア大学とハーバード大学の共同研究
https://www.lifehacker.jp/2017/08/170805_straighten-your-back-to-be-happy.html - 音楽を聴く: 不安レベルの低下が確認されています(論文
https://repository.kulib.kyoto-u.ac.jp/dspace/bitstream/2433/49406/1/16_89.pdf - 笑う: ストレス反応が大幅に下がります(論文
https://www.jstage.jst.go.jp/article/warai/10/0/10_KJ00000803466/_article/-char/ja/ - パートナーとのハグ: オキシトシン(通称愛情ホルモン)。ソロは(TT) 論文
https://ci.nii.ac.jp/naid/130004857151 - ペットをハグ: 上記と同じ効果(ペット飼いたいな…)(論文
https://www.jstage.jst.go.jp/article/janip/advpub/0/advpub_67.1.1/_pdf - スポーツ(ないしは筋トレ): 体を動かすのはストレス解消になる
https://www.jstage.jst.go.jp/article/jspeconf/41A/0/41A_25/_article/-char/ja/
因みに以前「読書」とは言われてたのだけど、論文を見つけることができなかった。
イギリスの方のニュースで広まったらしく
でもサセックス大学で研究があるとしか言ってない(要するに論文ではなかった)。
まぁ読書自体は良い事なので特に否定する気も起きないのですが…
因みに、ストレスが増えるとカリウムが不足するらしい。
ただしこれも論文見つけれなかった